New Project, Riffusion is a free web app that uses AI to create music from your text prompts
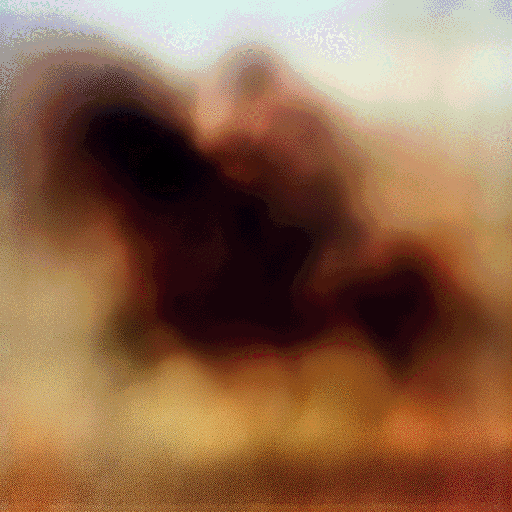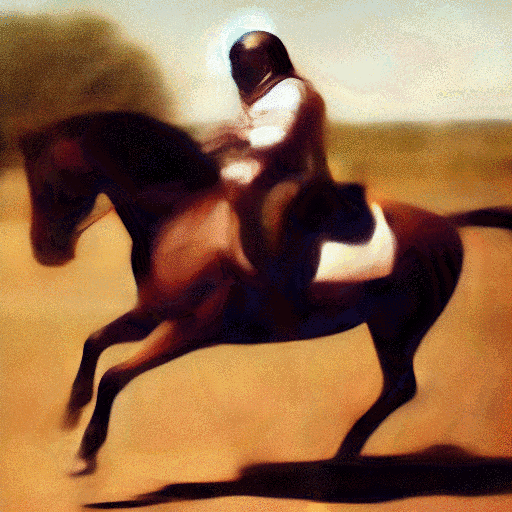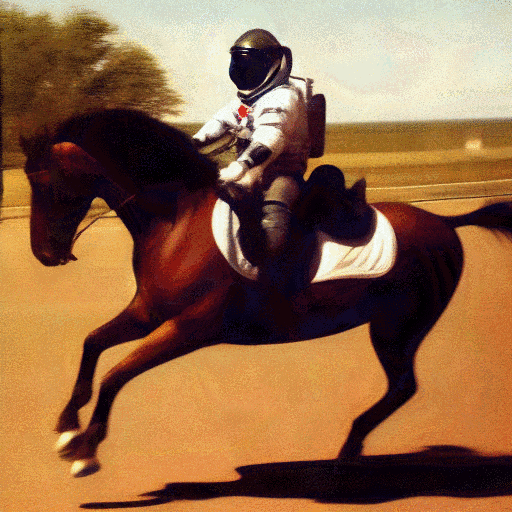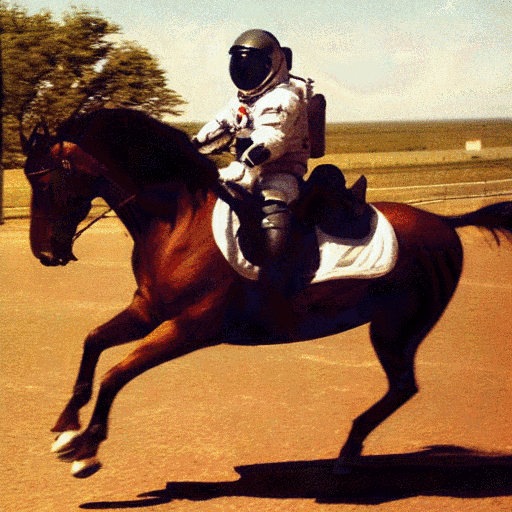
If you can type it, the robot can play it
You may well be aware of Stable Diffusion, the much-discussed open-source AI model that can generate images from text. Well, as a “hobby project”, developers – Seth Forsgren and Hayk Martiros – have now created Riffusion, which uses the same model to turn text into music.
With tools like Stable Diffusion, you can generate original images by supplying text prompts, like “photograph of an astronaut riding a horse”, as shown in the above image.
This artificial intelligence – so the program is not intentionally drawing a picture of an astronaut on a horse – it’s generating an image with qualities that are similar to the qualities of images that it’s indexed for ‘astronaut’ and ‘horse’.
This is an important difference, and helps explain why these AI images can be amazing, but are very likely to have some weirdness to them.
Did you notice that the horse only has three legs?
Riffusion is a new project that builds on the success of recent AI image generation work, but applies it to sound.
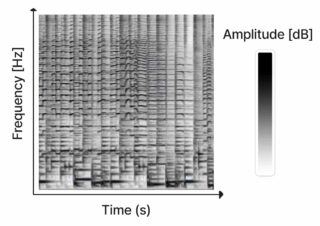
Riffusion works by generating images from spectograms, which are then converted into audio clips. We’re told that it can generate infinite variations of a text prompt by varying the ‘seed’.
Riffusion’s creators explain that a spectogram can be computed from audio using what’s known as the Short-time Fourier transform (STFT), which approximates the audio as a combination of sine waves of varying amplitudes and phases. But the process is limited by a small index of spectrograms, compared to the 2.3 billion images used to train Stable Diffusion. And it’s limited by the resolution of the spectrograms, which give the resulting audio a lofi quality.
However, in the case of Riffusion, the STFT is inverted so that the audio can be reconstructed from a spectogram. Here, the images from the AI model only contain the amplitude of the sine waves and not the phases – these are appromixmated by something called the Griffin-Lim algorithm when reconstructing the audio clip.

The web app enables you to type in prompts and will keep on generating interpolated content in realtime for as long as you let it, while giving you a visual 3D representation of the spectrogram. You can also skip immediately to the next prompt; if there isn’t one, Riffusion will interpolate between different seeds of the same prompt.
The approach shows potential, though. It’s currently up to the task of generating disturbing sample fodder – similar to the way AI image generation, even 6 months ago, was limited to generating lofi creepy images. This suggests that – with a much larger index, and higher resolution spectrograms – it’s likely that AI audio generation could make similar leaps in quality in the next year.
What do you think? Is there a future in music for AI directly synthesizing audio? Share your thoughts in the comments!
via John Lehmkuhl

























